
Работа с большими таблицами в Excel часто превращается в головоломку – особенно когда нужно перенести сложные формулы в Power BI. Представьте: у вас есть таблица с ключами, номерами и статусами, и нужно оставить только «валидные» строки по трём условиям. В Excel вы написали мегаформулу с вложенными IF, но в Power Query всё иначе. Давайте разберёмся, как перевести эту логику на язык M, сохранив чёткость и избежав хаоса.
Кстати, если вы раньше работали только с Excel-формулами, приготовьтесь к небольшому ментальному сдвигу. В Power Query мы не пишем условия в ячейках – мы трансформируем таблицу шаг за шагом, добавляя вспомогательные столбцы и анализируя данные через группировки. Это как собрать конструктор: каждое действие – отдельный кубик.
Почему Power Query вместо Excel?
Предположим, ваша таблица выглядит так (я немного упростил пример для наглядности):
| Key | Nr | Provisional | VALUE |
| RED1000 | 1 | Y | 14 |
| BLUE1001 | 2 | Y | 18 |
| YELLOW1002 | 1 | N | 30 |
В Excel вы проверяете каждое условие через COUNTIFS, но в Power Query такой подход не сработает. Вместо этого мы будем:
- Добавлять столбцы-маркеры для каждого условия валидности.
- Комбинировать их в итоговый фильтр.
- Удалять вспомогательные колонки, чтобы не засорять таблицу.
Главная тонкость – работа с контекстом. В Excel формулы «видят» всю таблицу, а в M-коде нужно явно указывать, к каким столбцам обращаться. Например, функция List.FindText ищет значения в конкретном списке (читай: столбце), а не во всём датасете.
Пошаговая реализация условий фильтрации в M
Вот как выглядит полный код (не пугайтесь, дальше будет подробный разбор):
let
Source = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
ChangeDataType = Table.TransformColumnTypes(Source,{{"Key", type text}, {"Nr", Int64.Type}, {"Provisional", type text}, {"VALUE", Int64.Type}}),
// Шаг 1: Проверка уникальности Key
KeyIsUnique = Table.AddColumn(ChangeDataType, "Unique Key",
each if List.Count(List.FindText(ChangeDataType[Key],[Key]))=1 then "Y" else null),
// Шаг 2: Создание временного столбца Key|Nr
AddTempCol = Table.AddColumn(KeyIsUnique, "Temp1", each [Key] & "|" & Number.ToText([Nr])),
// Шаг 3: Проверка Nr=1 при неуникальном Key
NrIsUnique = Table.AddColumn(AddTempCol, "NrIsUnique",
each if [Unique Key]=null then
if List.Count(List.FindText(AddTempCol[Temp1],[Temp1]))=1 and [Nr]=1 then "Y" else null
else null),
// Шаг 4: Создание временного столбца Key|Provisional
AddTempCol2 = Table.AddColumn(NrIsUnique, "Temp2", each [Key] & "|" & [Provisional]),
// Шаг 5: Проверка Provisional=N при неуникальных Key и Nr
ProvIsUnique = Table.AddColumn(AddTempCol2, "ProvIsUnique",
each if [Unique Key]=null and [NrIsUnique]=null then
if List.Count(List.FindText(AddTempCol2[Temp2],[Temp2]))=1 and [Provisional]="N" then "Y" else null
else null),
// Шаг 6: Объединение маркеров в итоговый столбец
AddValidRows = Table.AddColumn(ProvIsUnique, "VALID ROWS",
each Text.Combine({[Unique Key], [NrIsUnique], [ProvIsUnique]})),
// Шаг 7: Удаление вспомогательных столбцов
RemoveOtherColumns = Table.SelectColumns(AddValidRows,{"Key", "Nr", "Provisional", "VALUE", "VALID ROWS"})
in
RemoveOtherColumns Теперь разберём ключевые моменты:
Шаг 1: Проверка уникальности Key
Здесь используется List.FindText(ChangeDataType[Key],[Key]) – это ищет все вхождения текущего значения Key в столбце Key. Если количество найденных элементов (List.Count) равно 1 – ставим “Y”.
⚠️ Важно:
List.FindTextчувствителен к регистру. Если у вас есть ключи типа “Red1000” и “RED1000”, они будут считаться разными. Если это не нужно – используйтеList.Selectс сравнением черезText.Lower.
Шаг 3: Условие с Nr=1
Обратите внимание на конструкцию if [Unique Key]=null then ... – это значит, что мы проверяем Nr только для строк, где Key не уникален. Так мы избегаем ненужных вычислений.
Шаг 5: Работа с комбинированным ключом
Объединение Key и Provisional в Temp2 через разделитель “|” – обязательный трюк. Без этого List.FindText может дать ложные срабатывания (например, если Key=”A|B”, а Provisional=”C”, комбинация “A|BC” будет конфликтовать с “AB|C”).
Типичные ошибки и как их избежать
Вот что чаще всего ломает логику:
- Неправильные типы данных. Если Nr был импортирован как текст,
[Nr]=1всегда будет давать false. Всегда проверяйте типы в шагеChangeDataType. - Пропуск разделителя в Temp-столбцах. Если написать
[Key] & [Nr]вместо[Key] & "|" & [Nr], ключи “A12” и “A1|2” станут неразличимы. - Невнимательность к регистру.
[Provisional]="n"вместо[Provisional]="N"– и все строки с Provisional=”N” пролетят мимо фильтра.
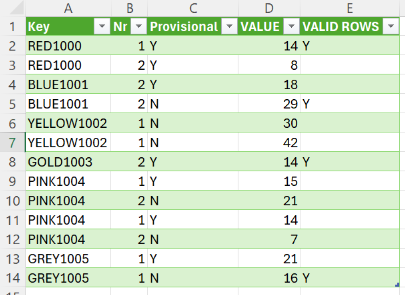
На скриншоте видно, как в итоговом столбце VALID ROWS комбинируются “Y” из трёх проверок. Чтобы отфильтровать только валидные строки, добавьте в конец кода:
FilteredRows = Table.SelectRows(RemoveOtherColumns, each [VALID ROWS] null)И ещё совет: если данные часто обновляются, обязательно проверьте, чтобы имя таблицы в Excel (Table1) совпадало с тем, что указано в первой строке кода. Это частая причина ошибок «Имя не найдено».