
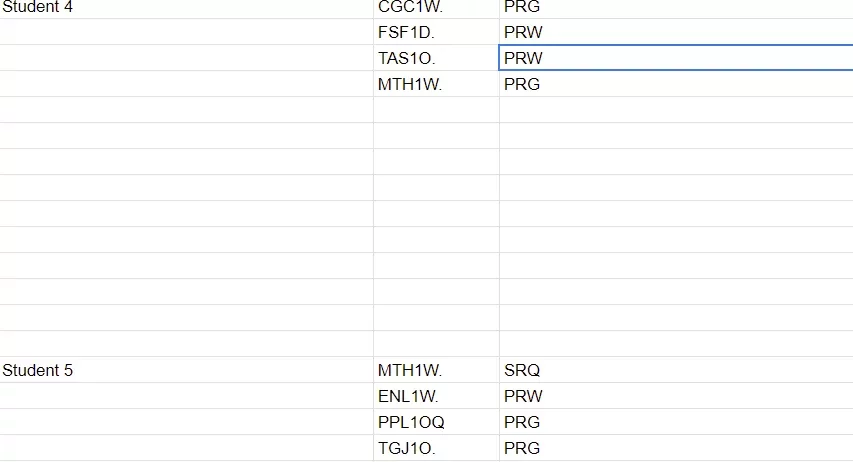
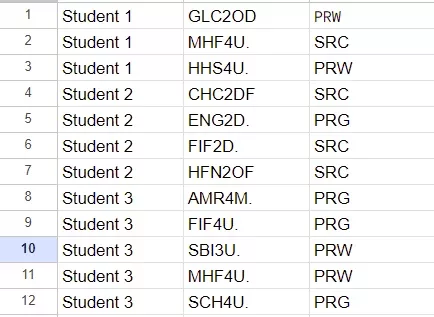
Представьте, что вы работаете с таблицей, где имена студентов указаны только один раз, а их курсы перечислены ниже — но между группами данных есть пустые строки. Задача: сделать так, чтобы каждому курсу соответствовало имя студента, и при этом избавиться от ненужных пробелов. Это типичный сценарий для учебных заведений или корпоративных отчётов, где данные структурированы «сверху вниз», но их нужно преобразовать в плоский формат для анализа.
Шаг 1: Подготовка данных и ключевые функции
Перед тем как браться за формулы, проверьте, что:
- Данные организованы в три колонки (например, Имя, Курс, Код курса).
- Пустые строки между группами — это действительно пустые ячейки, а не пробелы или скрытые символы (используйте
=TRIM(), если есть сомнения).
Основная идея решения — «протянуть» имя студента вниз до тех пор, пока не встретится следующее имя. Для этого понадобятся функции:
- XLOOKUP() — для поиска последнего непустого значения выше текущей ячейки.
- BYCOL() и MAP() — чтобы обработать каждую колонку отдельно и заполнить пропуски.
- FILTER() — чтобы удалить полностью пустые строки из исходных данных.
Кстати, если вы раньше использовали VLOOKUP() или ARRAYFORMULA(), этот подход покажется более гибким — особенно когда количество курсов у студентов варьируется от 1 до 5.
Шаг 2: Формула для автоматического заполнения
Создайте новый лист и вставьте эту формулу в ячейку A1:
=let(
fillDown_, lambda(data, let(a,data,r,max(bycol(a,lambda(l,index(ifna(xmatch("?*",to_text(l),2,-1))))),s,sequence(r),array_constrain(bycol(a,lambda(v,map(s,lambda(i,index(xlookup(i,s/(v""),v,,-1)))))),r,columns(a)))),
data, filter('working concepts'!A1:C, len('working concepts'!B1:B)),
fillDown_(data)
)Разберём логику по частям:
fillDown_— это пользовательская функция, созданная черезLAMBDA(). Она принимает массив данных (data) и для каждой колонки находит последнее непустое значение, чтобы заполнить пустоты.FILTER()удаляет строки, где колонка B (курсы) пустая — так мы избавляемся от ненужных разрывов.XMATCH("?*", ...)ищет ячейки с любым текстом (?*— регулярное выражение), чтобы определить, до какого ряда нужно «тянуть» данные.XLOOKUP(i, s/(v""), v, , -1)— ключевая часть. Здесьi— текущий номер строки,s/(v"")создаёт массив, где пустые ячейки игнорируются, а-1указывает на поиск ближайшего значения сверху.
Дополнительные рекомендации
- Если формула возвращает ошибку
#N/A, проверьте, что в исходных данных нет скрытых символов (например, переносов строк в ячейках). - Чтобы адаптировать формулу под большее количество колонок, измените диапазон
'working concepts'!A1:Cна нужный (например,A1:E). - Для визуального контроля добавьте условное форматирование: выделите колонку с именами и задайте правило
=A2A1с цветной заливкой — это поможет быстро найти места, где начинается новый студент.
Если вы впервые используете LAMBDA()-функции, не пугайтесь: их можно разбить на части. Например, сначала примените FILTER(), затем поэкспериментируйте с XLOOKUP() отдельно. Главное — понять, что алгоритм работает по принципу «запомнить последнее значение и повторять его, пока не встретится новое».
P.S. Если нужно объединить данные из нескольких листов, используйте {} — например, {Лист1!A1:C; Лист2!A1:C}. Но помните: формула автоматически не обновляется при добавлении новых листов — для этого потребуется скрипт Google Apps Script.